
Qu'est-ce que l'analyse de régression et pourquoi l'utilisons-nous dans notre plateforme de différenciation ?
De nombreux responsables qui utilisent notre plateforme d'IA savent qu'ils doivent prendre des décisions fondées sur des données dans le cadre de leur activité. L'un des principaux types d'analyse de données que nous utilisons est l'analyse de régression. Notre rôle n'est pas seulement de fournir les données, mais aussi d'aider à comprendre et à interpréter correctement les analyses effectuées.
L'analyse de régression est une méthode statistique puissante qui permet d'examiner la relation entre deux ou plusieurs variables d'intérêt. Elle fournit des informations détaillées qui peuvent être utilisées pour améliorer les produits et les services. Ceux-ci influencent à leur tour les ventes. Elle pose les questions suivantes : Quels sont les facteurs les plus importants ? Quels sont ceux que nous pouvons ignorer ? Comment ces facteurs interagissent-ils ? Et, ce qui est peut-être le plus important, dans quelle mesure sommes-nous certains de tous ces facteurs ?
Dans l'analyse de régression, ces facteurs sont appelés « variables ». Vous avez votre variable dépendante - le principal facteur que vous essayez de comprendre ou de prédire. Vous avez ensuite vos variables indépendantes, c'est-à-dire les facteurs qui, selon vous, ont un impact sur votre variable dépendante.
L'analyse de régression fournit des informations très détaillées qui peuvent être utilisées pour améliorer les produits et les services.
Chez LReply, nous proposons des formations pratiques sur nos plateformes, au cours desquelles les clients apprennent à maîtriser cet instrument pour mieux interpréter les résultats des enquêtes.
Par exemple, pour comprendre la valeur ajoutée de ces sessions de formation, nous distribuons des enquêtes de suivi aux participants pour savoir ce qu'ils ont aimé, ce qu'ils n'ont pas aimé et ce que nous pouvons améliorer pour les futures sessions.
Les données collectées à partir de ces enquêtes nous permettent de mesurer les niveaux de satisfaction que nos participants associent à nos événements, ainsi que les variables qui influencent ces niveaux de satisfaction.
S'agit-il des thèmes abordés lors des différentes sessions de l'événement ? La durée de la session ? La date de la session ? La nourriture ou les services de restauration fournis ? Le coût de la participation ? Toutes ces variables peuvent avoir un impact sur le niveau de satisfaction des participants.
En effectuant une analyse de régression sur les données de l'enquête, nous pouvons déterminer si ces variables ont eu un impact sur la satisfaction globale des participants, et si oui, dans quelle mesure.
Ces informations nous indiquent quels sont les éléments des sessions qui ont été bien accueillis et ce sur quoi nous devons nous concentrer pour que les participants soient plus satisfaits à l'avenir.
Comment fonctionne l'analyse de régression ?
Dans notre exemple de formation, la satisfaction des participants à l'égard de l'événement est notre variable dépendante. Les sujets abordés, la durée des sessions, la nourriture fournie et le coût de la participation sont nos variables indépendantes.
Dans ce cas, nous aimerions mesurer les niveaux historiques de satisfaction à l'égard d'un événement au cours des trois dernières années environ (ou toute autre période que vous jugerez statistiquement significative), ainsi que toutes les informations possibles sur les variables indépendantes.
Nous serions particulièrement intéressés de savoir comment le prix d'entrée à l'événement affecte les niveaux de satisfaction.
La ligne de régression représente la relation entre notre variable indépendante et notre variable dépendante.
La formule d'une droite de régression peut ressembler à Y = 50 + 7X + terme d'erreur.
Si X est l'augmentation du prix de la participation, cela signifie que si le prix de la participation n'augmente pas, la satisfaction à l'égard de l'événement augmentera tout de même de 50 points.
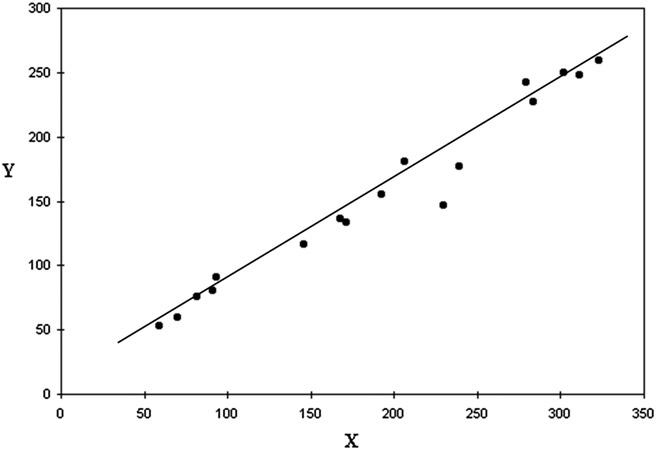
Notre ligne de régression est simplement une estimation basée sur les données dont nous disposons. Par conséquent, plus le terme d'erreur est élevé, moins notre droite de régression est sûre.
Il est important de noter que la corrélation n'est pas la causalité : Chaque fois que vous travaillez avec une analyse de régression, ou toute autre analyse qui tente d'expliquer l'impact d'un facteur sur un autre, vous devez vous souvenir d'un adage important : « Corrélation n'est pas causalité ». Cet adage est essentiel. Voici pourquoi : Il est facile de dire qu'il existe une corrélation entre la pluviométrie et les ventes mensuelles. La régression montre qu'ils sont effectivement liés. Mais il est tout à fait différent d'affirmer que la pluie est à l'origine des ventes. À moins de vendre des parapluies, il peut être difficile de prouver un lien de causalité direct.
Il est également important de ne pas laisser les données remplacer l'intuition. C'est pourquoi nous recommandons de toujours superposer votre intuition aux données. Demandez-vous si les résultats correspondent à votre compréhension de la situation. Et si vous constatez que quelque chose n'a pas de sens, demandez-vous si les données étaient correctes ou s'il y a effectivement un terme d'erreur significatif.
Si vous pensez que les données n'ont pas de sens, nous pouvons vous aider. Toute analyse doit être accompagnée d'une étude en situation réelle. Même les meilleurs scientifiques et gestionnaires tiennent toujours compte de ces deux éléments.




